
Last week, we got introduced to SQL Server’s query Execution Plans, looked at how we can view them in SQL Server Management Studio (SSMS). In this episode, let’s dig a bit deeper into Execution Plans by getting familiarized with a few of the common operators that you’ll encounter when reading them. These operators tell us the type of work that SQL Server has to do, in order to fulfill our request. Some operations are expensive – they require more time and server resources to complete while others, relatively speaking, are simpler operations. Understanding the various types will give us the insight needed, to modify our queries in such a way that some of the expensive operations are avoided, and in turn, achieve better overall performance of our queries.
I want to stress here that no single operator is inherently bad or good. It really depends on your unique query and situations surrounding them. Performance Tuning, as the word tuning in that term suggests, is adjusting the operations of your database to meet the specific goals that you are seeking to meet.
Table Scan
A table scan is when the SQL Server Engine has to go through the contents of a table, row by row, to find the specific ones, pertinent to our query. Your situation may actually necessitate such a need but you should ask yourself if there is an index that you can add that will alleviate the burden of this query.
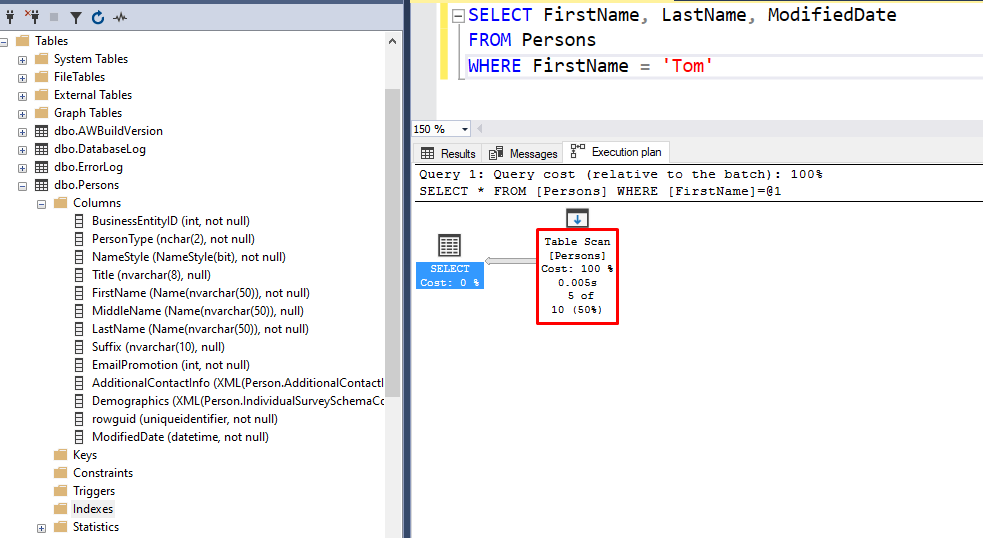
In the example above, I have a Persons table that has no indexes of any kind. With any query against this table, SQL server will have no choice but to go through each row and see if it meets the conditions of my query.
Index Seek
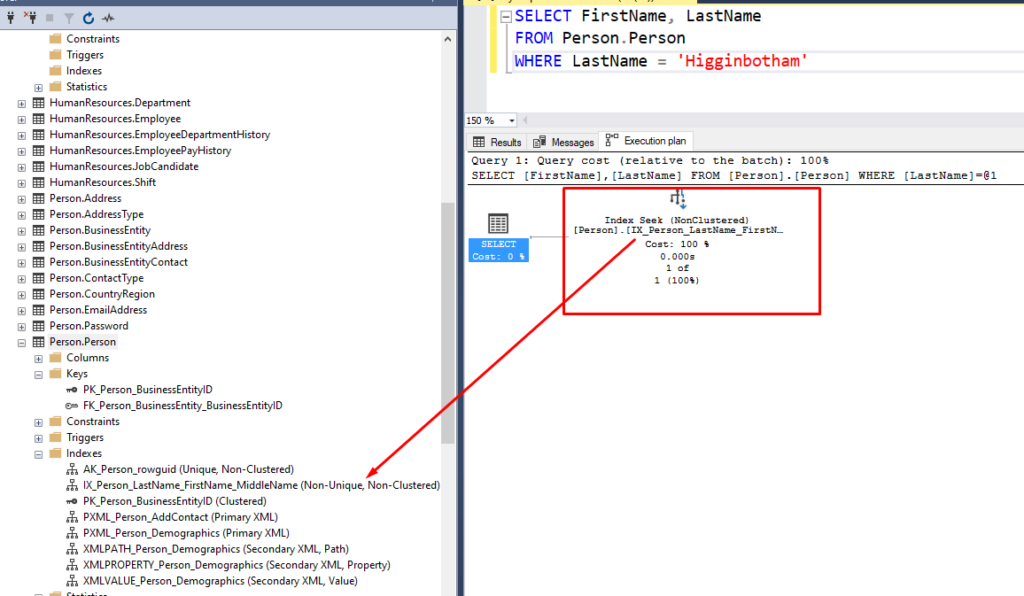
Another operator that you’ll likely come across is an Index Seek. Generally speaking, this is considered a good sign because SQL Server has found an index on the table that it can use to short-circuit the process of finding your data. In the example above, there is an non-clustered index on the LastName, Firstname and MiddleName columns and it can use that index to directly grab the results that I’m querying instead of having to scan every single row to obtain matching results.
Key Lookup (and Nested Loops Join)
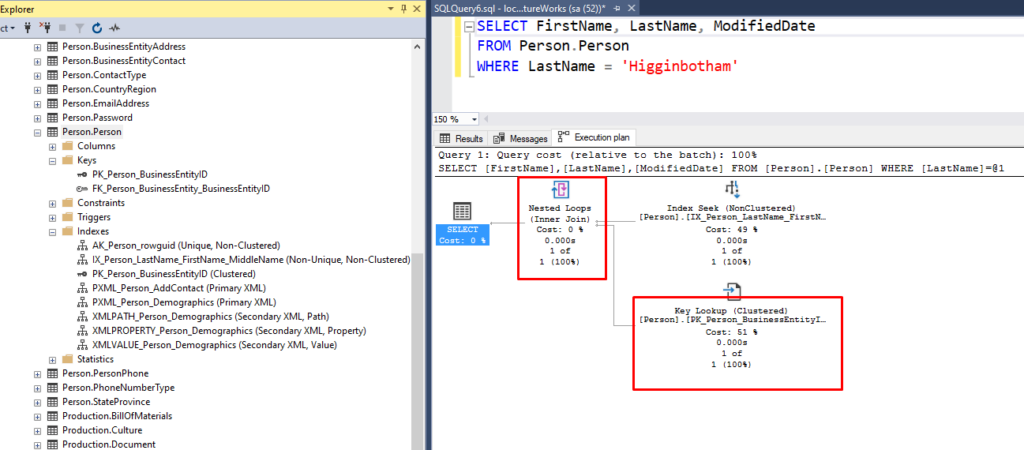
Consider the example below which is a slight variation of the index scan example from earlier. The only difference here is that I added the ModifiedDate column to my SELECT list. In this case, SQL server was still able to use the same index as it previously did but since the index didn’t contain the ModifiedDate column, it had to then look up the associated ModifiedDate value for each matching record from the table. That is essentially what a Key Lookup operator does – lookup values that were not present in the index.
This example also introduced yet another operator – Nested Loop Join. In this particular example, it has the job of combining the data from the Index Seek (FirstNames and LastNames) with the associated data from the Key Lookup (ModifiedDate) into a single combined result set. We’ll look at a few more physical join operators, a little later in this article.
Index Scan
Let’s modify the above query to get all Person records that have a LastName containing the string Higg.
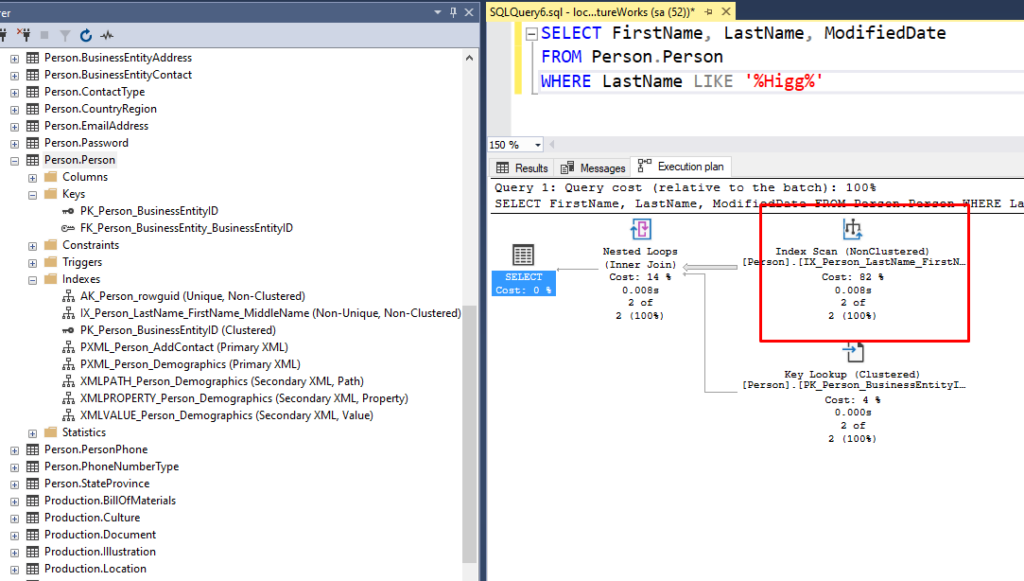
In this example, SQL Server is using the same name index that’s available on the table but it has the scan the entire contents of that index. That is because I have added wildcards to both the beginning and the ending of my search string ('%Higg%'). As such, SQL Server knows that it can still use the name index but it must read each one to see if the last name contains the specific phrase that I’m looking for. If on the other hand, if I had added the wildcard to just the end of the phrase ('Higg%'), it can still seek the index instead of doing a scan, a less costly operation in this particular example.
Sort
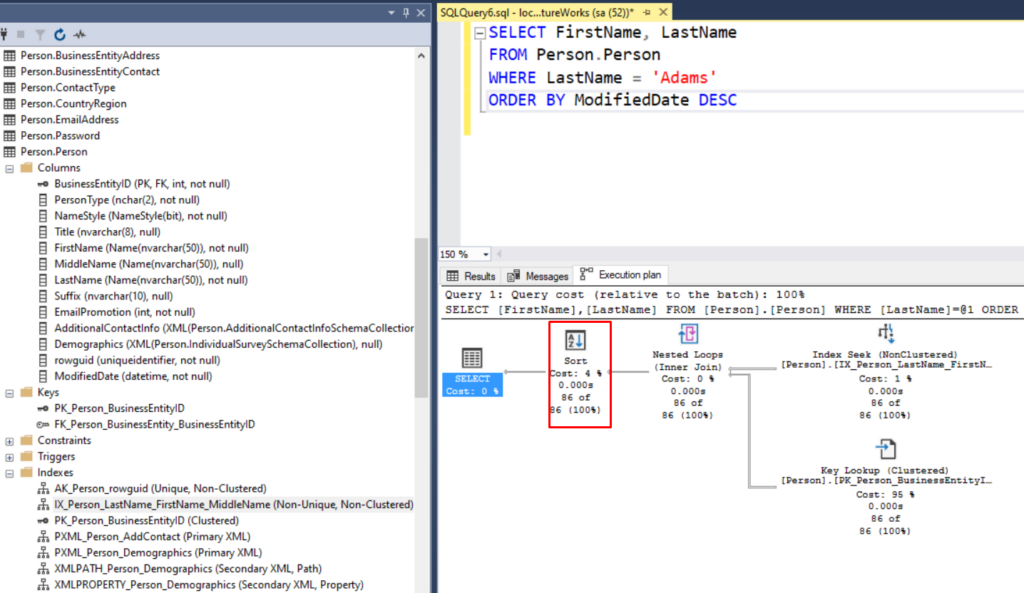
Another operator that you’ll often encounter is a sort operator. Generally speaking, this is another operator that can be quite taxing so if you see that it represents a large cost percentage of your query execution, you should consider adding a index on that column in the same order that you want that data to be retrieved so that SQL Server can minimize or avoid incurring that operator cost.
Physical Join Operators
Nested Loop Joins
We saw an example of a Nested Loop Join earlier. For each item in result set A, the engine loops over all items in result set B to find matches and then it compiles a combined result set.
Merge Joins
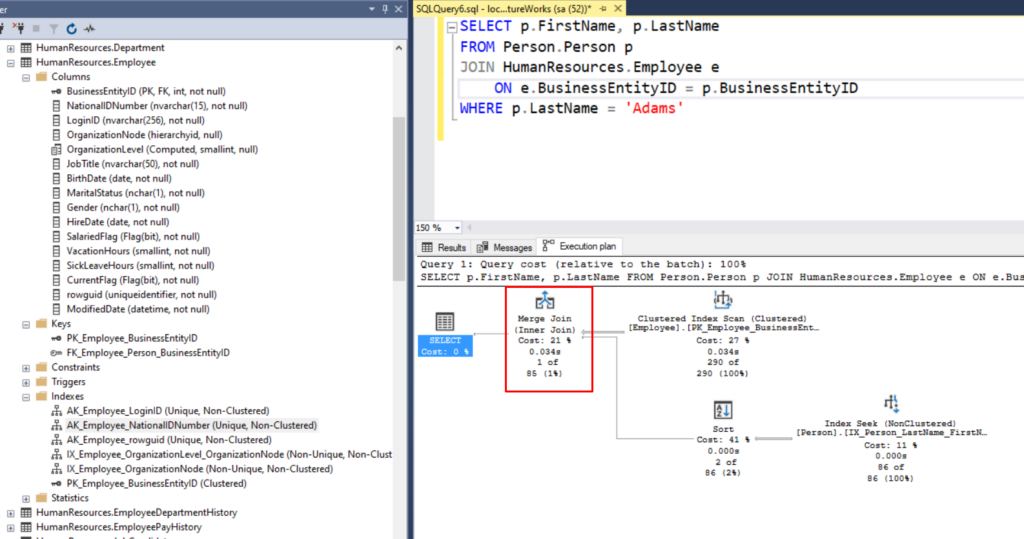
This is an operation where SQL Server gets two result sets that are already sorted. Unlike the nested loop join where SQL server would need to traverse the entirety of result set B for each item in A, it can simply traverse the items until it reaches the end of that particular batch because it knows that there won’t be any additional matches in the remaining rows.
Hash Match Joins
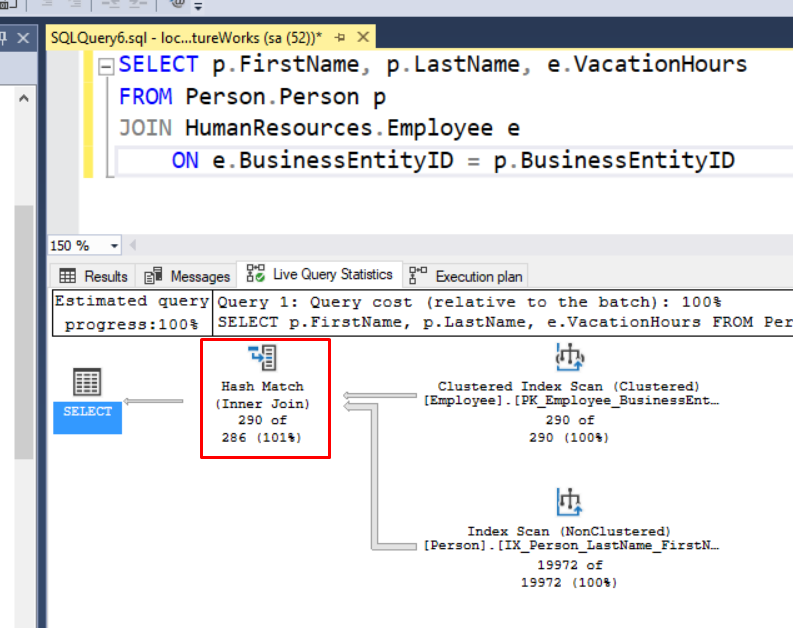
For this operation, SQL Server creates a hash table of all the values in a result set and probes each item in the second set; when it finds a hash match, that item is gathered in the new result set for the next operation.
Spools
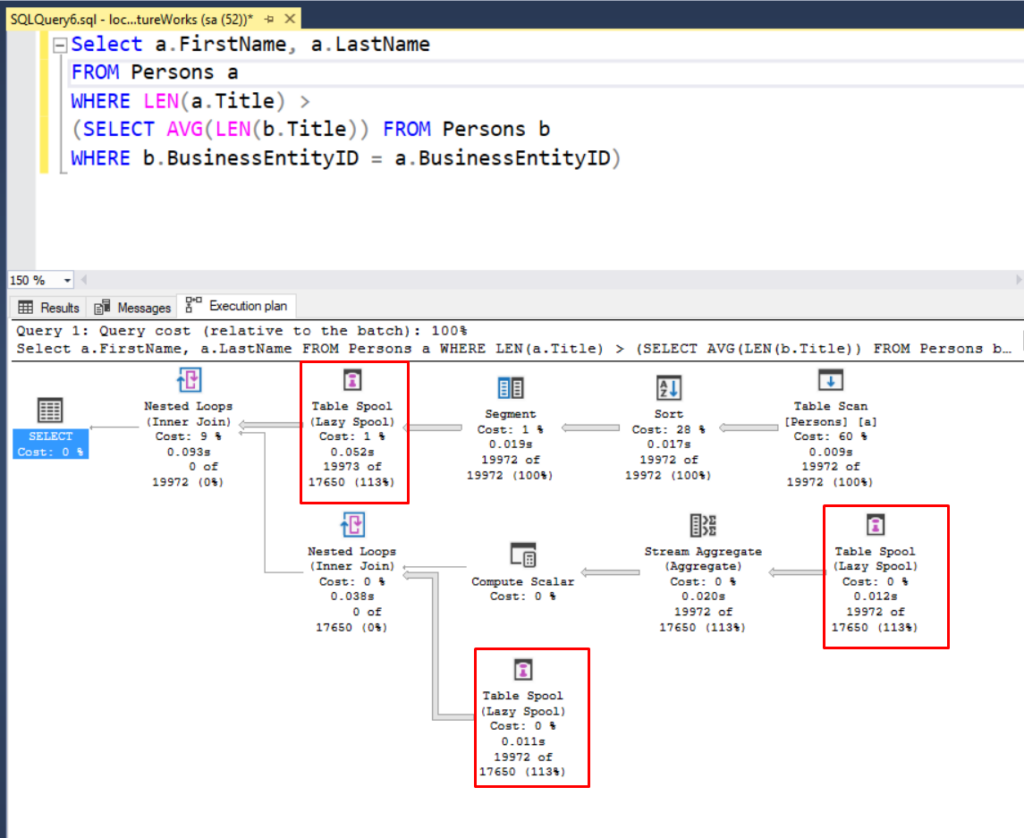
For this operation, SQL Server stages some data into a temporary structure for further operations to be carried out. Depending on the workload, SQL Server may create this spool in memory or in some cases, it will create the structure in tempdb. Writes out to disk can certainly play a factor on your query’s performance so you may want to pay close attention to see if the engine is working your query in a way that makes sense.
Parallelism
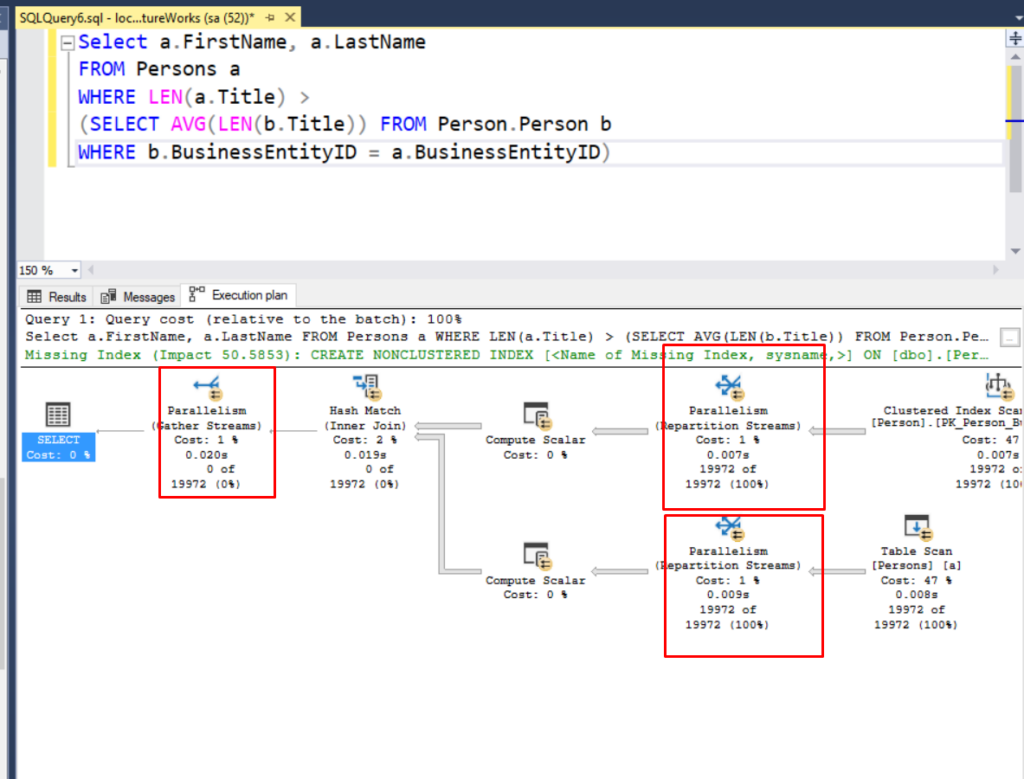
In scenarios where the SQL Server engine has access to multiple processors, it can distribute the workload among them and gather and combine the results to produce the output for a query. Although this can speed up the overall work, it could also lead to poor performance in some cases too. There is a bit of overhead in divvying up the work and there is also additional overhead in gathering up the results from the various worker processes. In some cases that overhead is acceptable that it still results in a faster execution than if the work was done serially. However, in some cases, the overhead could have a higher cost than if the work was done on a single processor.
Parting Thoughts
Today, we looked at some of the common operators that you’ll encounter when reading an execution plan. Having a better understanding of them will help in identifying potential bottlenecks in your query and give you ideas on how you can restructure your work to increase its performance.
If you have missed the previous posts in this series, you can check them out here: